10.11 BERT
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
10.11.1 原理
简而言之,BERT在预训练阶段提取通用的语义特征,再在下游任务处根据需要进行微调。
10.11.1.1 整体结构
BERT只用了Transformer的Encoder部分,并且堆叠多个Encoder。
\[ x_l' = x_l + \text{Attention}(\text{LN}(x_l)) \\ x_{l+1} = x_l'+\text{FFN}(\text{LN}(x_l')) \]
Encoder中的注意力机制能够看到上下文信息,体现“双向”
10.11.1.2 模型输入
BERT相较于Transformer,除了词嵌入和位置编码外,还有Segment Embedding。
Token Embedding
采用WordPiece的方法进行词嵌入。
Position Embedding
可学习的绝对位置向量。
对序列长度有要求,不能外推更长的序列
Segment Embedding
可学习的向量,用来标记句子属于第一句还是第二句。
最后模型输入表示为
\[ E= E_{token}+E_{position}+E_{segment} \]
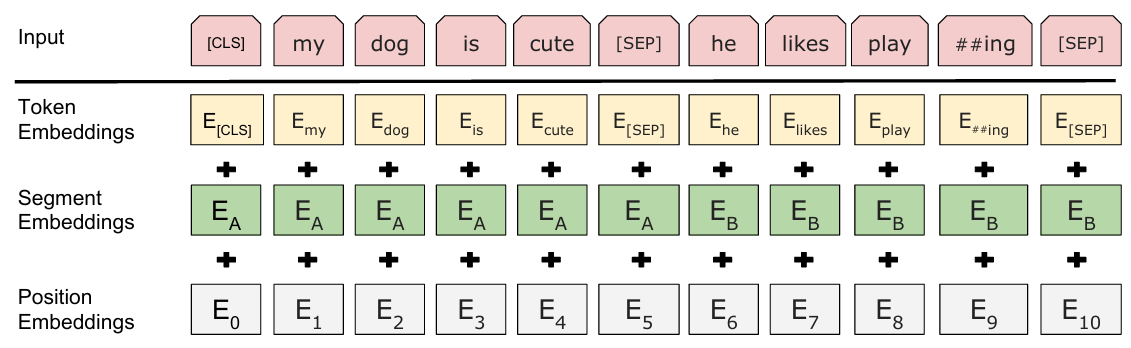
图 10.7: input
10.11.1.3 预训练
实际中有大量无标签文本,要从中学习到通用的语义特征,就要采取子监督学习的方法。
Masked Language Modeling
随机抽取一部分token记为
[Mask],对其采取三种策略:(1)记为[Mask];(2)替换为其他随机词;(3)保留为原词。这样做是因为在推理时不会存在
[Mask],去掉一部分[Mask]有助于训练-推理保持一致性。
MLM任务就是预测
[Mask]处的原始token,即使它是随机token还是原tokenMask时能够看到上下文信息,也体现了“双向”
Next Sentence Prediction
输入A+B的句子,其中B有50%是真实的A的下一个句子,50%是随机的句子。并使用特殊的隐状态C用于NSP任务的分类预测。