GPT-1
Improving Language Understanding by Generative Pre-Training
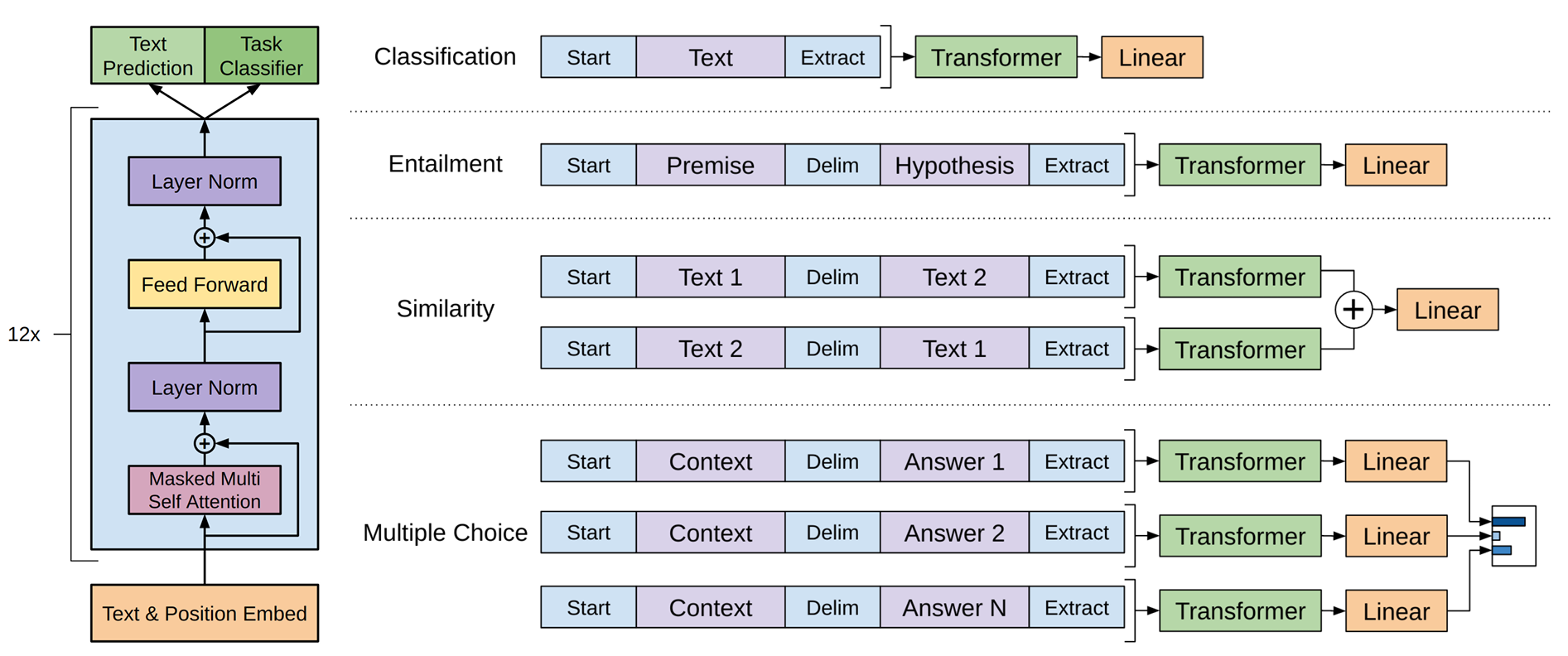
整体结构
仅采用Transformer的Decoder部分。由于没有编码器部分,所以去除了其中的交叉注意力机制。
模型输入
根据下游任务的不同有不同的输入方式,但基本都包含Token Embedding和Position Embedding。
此处的PE采取可学习的绝对位置编码
预训练
GPT在无标记文本上进行预训练,采用标准语言模型的目标函数,即似然函数,根据给定的前k个词预测下一个词。
\[
L_1 = \sum_i \log{P(u_i|u_{i-k}, \cdots,u_{i-1};\Theta)}
\]
其网络结构为
\[
\begin{gather}
h_0 = UW_e+W_p \\
h_l = \text{transformer_block}(h_{l-1}) \\
P(u) = \text{softmax}(h_nW_e^T)
\end{gather}
\]
其中\(W_e\)和\(W_p\)分别表示词嵌入矩阵、位置编码矩阵。
输出的时候也经过\(W_e\)的线性变换,是为了找到\(h_n\)与已有词表的哪个词最为相似
微调
对于有标记的样本对x和y,每次输入序列为x,标签为y,损失函数为
\[
L_2=\sum_{x,y}\log{P(y|x^1, \dots, x^m)}
\]
则总体损失函数为
\[
L_3 = L_2+\lambda \cdot L_1
\]
其中\(\lambda\)是调节参数。
不同下游任务可更换不同的输入形式,并适当调整输出结构。
GPT-2
GPT-2除了规模上比GPT-1更大外,主要的改变就是Zero-shot。
Zero-shot,零样本学习,指模型在没有见过该任务训练数据的情况下,仅通过自然语言指令(prompt)就能执行任务。
不用微调
例如
翻译为英文:我喜欢猫
其中“翻译为英文”就是提示词。
为什么提示词有效?
提示词工程:(1)指令提示;(2)零样本提示;(3)少样本提示;(4)思维链提示;(5)角色提示
GPT-3
GPT-3的训练规模进一步扩大。
GPT-2基于Zero-shot理念,而GPT-3除了Zero-shot外还有Few-shot,也称之为In-context Learning。
GPT-3在预训练之后,只要给模型提示词、任务描述、几个示例,模型就能够输出相应的结果,这个过程不会进行梯度更新。
不用微调